Fairsharing and Job Accounting¶
- Resources:
- Slurm Priority, Fairshare and Fair Tree (PDF)
- SchedMD Slurm documentation: Multifactor Priority Plugin
- Fair tree algorithm, FAS RC docs, Official
ssharedocumentation
Fairshare allows past resource utilization information to be taken into account into job feasibility and priority decisions to ensure a fair allocation of the computational resources between the all ULHPC users. A difference with a equal scheduling is illustrated in the side picture (source).
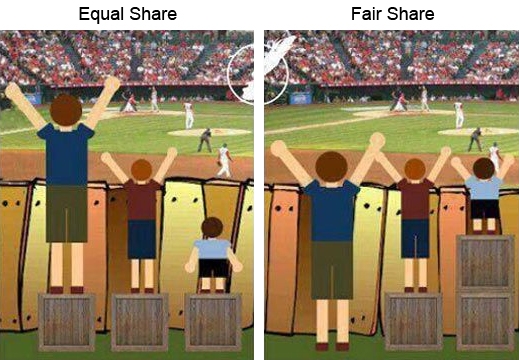
Essentially fairshare is a way of ensuring that users get their appropriate portion of a system. Sadly this term is also used confusingly for different parts of fairshare listed below, so for the sake of clarity, the following terms will be used:
- [Raw] Share: portion of the system users have been granted
- [Raw] Usage: amount of the system users have actually used so far
- The fairshare score is the value the system calculates based on the usage and the share (see below)
- Priority: the priority that users are assigned based off of their fairshare score.
Demystifying Fairshare
While fairshare may seem complex and confusing, it is actually quite logical once you think about it. The scheduler needs some way to adjudicate who gets what resources when different groups on the cluster have been granted different resources and shares for various reasons (see Account Hierarchy).
In order to serve the great variety of groups and needs on the cluster, a method of fairly adjudicating job priority is required. This is the goal of Fairshare. Fairshare allows those users who have not fully used their resource grant to get higher priority for their jobs on the cluster, while making sure that those groups that have used more than their resource grant do not overuse the cluster.
The ULHPC supercomputers are a limited shared resource, and Fairshare ensures everyone gets a fair opportunity to use it regardless of how big or small the group is.
FairTree Algorithm¶
There exists several fairsharing algorithms implemented in Slurm:
- Classic Fairshare
- Depth-Oblivious Fair-share
- Fair Tree (now implemented on ULHPC since Oct 2020)
What is Fair Tree?
The Fair Tree algorithm prioritizes users such that if accounts A and B are siblings and A has a higher fairshare factor than B, then all children of A will have higher fairshare factors than all children of B.
This is done through a rooted plane tree (PDF), also known as a rooted ordered tree, which is logically created then sorted by fairshare with the highest fairshare values on the left. The tree is then visited in a depth-first traversal way. Users are ranked in pre-order as they are found. The ranking is used to create the final fairshare factor for the user. Fair Tree Traversal Illustrated -- initial post.
Some of the benefits include:
- All users from a higher priority account receive a higher fair share factor than all users from a lower priority account.
- Users are sorted and ranked to prevent errors due to precision loss. Ties are allowed.
- Account coordinators cannot accidentally harm the priority of their users relative to users in other accounts.
- Users are extremely unlikely to have exactly the same fairshare factor as another user due to loss of precision in calculations.
- New jobs are immediately assigned a priority.
Overview of Fair Tree for End Users Level Fairshare Calculation
Shares¶
On ULHPC facilities, each user is associated by default to a meta-account reflecting its direct Line Manager within the institution (Faculty, IC, Company) you belong too -- see ULHPC Account Hierarchy. You may have other account associations (typically toward projects accounts, granting access to different QOS for instance), and each accounts have Shares granted to them. These Shares determine how much of the cluster that group/account has
been granted. Users when they run are charged back for their runs against the account used upon job submission -- you can use sbatch|srun|... -A <account> [...] to change that account.
Different rules are applied to define these weights/shares depending on the level in the hierarchy:
- L1 (Organizational Unit): arbitrary shares to dedicate at least 85% of the platform to serve UL needs and projects
- L2: function of the out-degree of the tree nodes, reflecting also the past year funding
- L3: a function reflecting the budget contribution of the PI/project (normalized on a per-month basis) for the year in exercise.
- L4 (ULHPC/IPA login): efficiency score, giving incentives for a more efficient usage of the platform.
Fair Share Factor¶
The Fairshare score is the value Slurm calculates based off of user's usage reflecting the difference between the portion of the computing resource that has been promised (share) and the amount of resources that has been consumed. It thus influences the order in which a user's queued jobs are scheduled to run based on the portion of the computing resources they have been allocated and the resources their jobs have already consumed.
In practice, Slurm's fair-share factor is a floating point number between 0.0 and 1.0 that reflects the shares of a computing resource that a user has been allocated and the amount of computing resources the user's jobs have consumed.
- The higher the value, the higher is the placement in the queue of jobs waiting to be scheduled.
- Reciprocally, the more resources the users is consuming, the lower the fair share factor will be which will result in lower priorities.
ulhpcshare helper¶
Listing the ULHPC shares: ulhpcshare helper
sshare can be used to view the fair share factors and corresponding promised and actual usage for all users. However, you are encouraged to use the ulhpcshare helper function:
# your current shares and fair-share factors among your associations
ulhpcshare
# as above, but for user '<login>'
ulhpcshare -u <login>
# as above, but for account '<account>'
ulhpcshare -A <account>
Official sshare utility¶
ulhpcshare is a wrapper around the official sshare utility. You can quickly see your score with
$ sshare [-A <account>] [-l] [--format=Account,User,RawShares,NormShares,EffectvUsage,LevelFS,FairShare]
Level FS. The field shows the value for each association, thus allowing users to see the results of the fairshare calculation at each level.
Note: Unlike the Effective Usage, the Norm Usage is not used by Fair Tree but is still displayed in this case.
Slurm Parameter Definitions¶
In this part some of the set slurm parameters are explained which are used to set up the Fair Tree Fairshare Algorithm. For a more detailed explanation please consult the official documentation
PriorityCalcPeriod=HH:MM::SS: frequency in minutes that job half-life decay and Fair Tree calculations are performed.PriorityDecayHalfLife=[number of days]-[number of hours]: the time, of which the resource consumption is taken into account for the Fairshare Algorithm, can be set by this.PriorityMaxAge=[number of days]-[number of hours]: the maximal queueing time which counts for the priority calculation. Note that queueing times above are possible but do not contribute to the priority factor.
A quick way to check the currently running configuration is:
scontrol show config | grep -i priority
Trackable RESources (TRES) Billing Weights¶
Slurm saves accounting data for every job or job step that the user submits. On ULHPC facilities, Slurm Trackable RESources (TRES) is enabled to allow for the scheduler to charge back users for how much they have used of different features (i.e. not only CPU) on the cluster -- see Job Accounting and Billing. This is important as the usage of the cluster factors into the Fairshare calculation.
As explained in the ULHPC Usage Charging Policy, we set TRES for CPU, GPU, and Memory usage according to weights defined as follows:
| Weight | Description |
|---|---|
| \alpha_{cpu} | Normalized relative performance of CPU processor core (ref.: skylake 73.6 GFlops/core) |
| \alpha_{mem} | Inverse of the average available memory size per core |
| \alpha_{GPU} | Weight per GPU accelerator |
Each partition has its own weights (combined into TRESBillingWeight) you can check with
# /!\ ADAPT <partition> accordingly
scontrol show partition <partition>
ULHPC Usage Charging Policy¶
The advertised prices are for internal partners only
The price list and all other information of this page are meant for internal partners, i.e., not for external companies. If you are not an internal partner, please contact us at hpc-partnership@uni.lu. Alternatively, you can contact LuxProvide, the national HPC center which aims at serving the private sector for HPC needs.
How to estimate HPC costs for projects?¶
You can use the following excel document to estimate the cost of your HPC usage:
UL HPC Cost Estimates for Project Proposals [xlsx]
Note that there are two sheets offering two ways to estimate based on your specific situation. Please read the red sections to ensure that you are using the correct estimation sheet.
Note that even if you plan for large-scale experiments on PRACE/EuroHPC supercomputers through computing credits granted by Call for Proposals for Project Access, you should plan for ULHPC costs since you will have to demonstrate the scalability of your code -- the University's facility is ideal for that. You can contact hpc-partnership@uni.lu for more details about this.
HPC price list - 2022-10-01¶
Note that ULHPC price list has been updated, see below.
Compute¶
| Compute type | Description | € (excl. VAT) / node-hour |
|---|---|---|
| CPU - small | 28 cores, 128 GB RAM | 0.25€ |
| CPU - regular | 128 cores, 256 GB RAM | 1.25€ |
| CPU - big mem | 112 cores, 3 TB RAM | 6.00€ |
| GPU | 4 V100, 28 cores, 768 GB RAM | 5.00€ |
The prices above correspond to a full-node cost. However, jobs can use a fraction of a node and the price of the job will be computed based on that fraction. Please find below the core-hour / GPU-hour costs and how we compute how much to charge:
| Compute type | Unit | € (excl. VAT) |
|---|---|---|
| CPU - small | Core-hour | 0.0089€ |
| CPU - regular | Core-hour | 0.0097€ |
| CPU - big mem | Core-hour | 0.0535€ |
| GPU | GPU-hour | 1.25€ |
For CPU nodes, the fraction correspond to the number of requested cores, e.g. 64 cores on a CPU - regular node corresponds to 50% of the available cores and thus will be charged 50% of 1.25€.
Regarding the RAM of a job, if you do not override the default behaviour, you will receive a percentage of the RAM corresponding to the amount of requested cores, e.g, 128G of RAM for the 64 cores example from above (50% of a CPU - regular node). If you override the default behaviour and request more RAM, we will re-compute the equivalent number of cores, e.g. if you request 256G of RAM and 64 cores, we will charge 128 cores.
For GPU nodes, the fraction considers the number of GPUs. There are 4 GPUs, 28 cores and 768G of RAM on one machine. This means that for each GPU, you can have up to 7 cores and 192G of RAM. If you request more than those default, we will re-compute the GPU equivalent, e.g. if you request 1 GPU and 8 cores, we will charge 2 GPUs.
Storage¶
| Storage type | € (excl. VAT) / GB / Month | Additional information |
|---|---|---|
| Home | Free | 500 GB |
| Project | 0.02€ | 1 TB free |
| Scratch | Free | 10 TB |
Note that for project storage, we charge the quota and not the used storage.
HPC Resource allocation for UL internal R&D and training¶
ULHPC resources are free of charge for UL staff for their internal work and training activities. Principal Investigators (PI) will nevertheless receive on a regular basis a usage report of their team activities on the UL HPC platform. The corresponding accumulated price will be provided even if this amount is purely indicative and won't be charged back.
Any other activities will be reviewed with the rectorate and are a priori subjected to be billed.
Submit project related jobs¶
To allow the ULHPC team to keep track of the jobs related to a project, use the -A <projectname> flag in Slurm, either in the Slurm directives preamble of your script, e.g.,
#SBATCH -A myproject
or on the command line when you submit your job, e.g., sbatch -A myproject /path/to/launcher.sh
FAQ¶
Q: My user fairshare is low, what can I do?¶
We have introduced an efficiency score evaluated on a regular basis (by default, every year) to measure how efficient you use the computational resources of the University according to several measures for completed jobs:
- How efficient you were to estimate the walltime of your jobs (Average Walltime Accuracy)
- How CPU/Memory efficient were your completed jobs (see
seff)
Without entering into the details, we combine these metrics to compute an unique score value S_\text{efficiency} and you obtain a grade: A (very good), B, C, or D (very bad) which can increase your user share.
Q: My account fairshare is low, what can I do?¶
There are several things that can be done when your fairshare is low:
- Do not run jobs: Fairshare recovers via two routes.
- The first is via your group not running any jobs and letting others use the resource. That allows your fractional usage to decrease which in turn increases your fairshare score.
- The second is via the half-life we apply to fairshare which ages out old usage over time. Both of these method require not action but inaction on the part of your group. Thus to recover your fairshare simply stop running jobs until your fairshare reaches the level you desire. Be warned this could take several weeks to accomplish depending on your current usage.
- Be patient, as a corollary to the previous point. Even if your fairshare is low, your job gains priority by sitting the queue (see Job Priority). The longer it sits the higher priority it gains. So even if you have very low fairshare your jobs will eventually run, it just may take several days to accomplish.
- Leverage Backfill: Slurm runs in two scheduling loops.
- The first loop is the main loop which simply looks at the top of the priority chain for the partition and tries to schedule that job. It will schedule jobs until it hits a job it cannot schedule and then it restarts the loop.
- The second loop is the backfill loop. This loop looks through jobs further down in the queue and asks can I schedule this job now and not interfere with the start time of the top priority job. Think of it as the scheduler playing giant game of three dimensional tetris, where the dimensions are number of cores, amount of memory, and amount of time. If your job will fit in the gaps that the scheduler has it will put your job in that spot even if it is low priority. This requires you to be very accurate in specifying the core, memory, and time usage (typically below) of your job. The better constrained your job is the more likely the scheduler is to fit you in to these gaps. The
seffutility is a great way of figuring out your job performance.
- Plan: Better planning and knowledge of your historic usage can help you better budget your time on the cluster. Our clusters are not infinite resources. You have been allocated a slice of the cluster, thus it is best to budget your usage so that you can run high priority jobs when you need to.
- HPC Budget contribution: If your group has persistent high demand that cannot be met with your current allocation, serious consideration should be given to contributing to the ULHPC budget line.
- This should be done for funded research projects -- see HPC Resource Allocations for Research Project
- This can be done by each individual PI, Dean or IC director. In all cases, any contribution on year
Ygrants additional shares for the group starting yearY+1. We apply a consistent (complex) function taking into account depreciation of the investment. Contact us (by mail or by a ticket) for more details.