ULHPC GPU Nodes¶
Each GPU node provided as part of the gpu partition feature 4x Nvidia V100 SXM2 (with either 16G or 32G memory) interconnected by the NVLink 2.0 architecture
NVlink was designed as an alternative solution to PCI Express with higher bandwidth and additional features (e.g., shared memory) specifically designed to be compatible with Nvidia's own GPU ISA for multi-GPU systems -- see wikichip article.
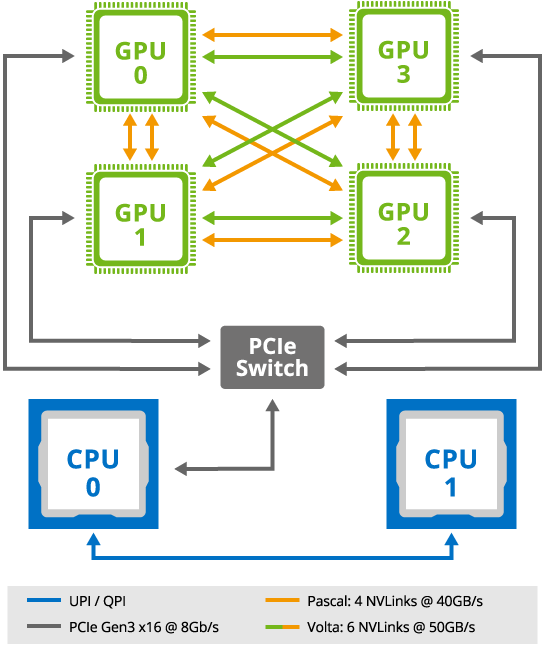
Because of the hardware organization, you MUST follow the below recommendations:
- Do not run jobs on GPU nodes if you have no use of GPU accelerators!, i.e. if you are not using any of the software compiled against the
{foss,intel}cudatoolchain. - Avoid using more than 4 GPUs, ideally within the same node.
- Dedicated ¼ of the available CPU cores for the management of each GPU card reserved.
Thus your typical GPU launcher would match the AI/DL launcher example:
#!/usr/bin/bash --login
#SBATCH --job-name=gpu_example
#SBATCH --output=%x-%j.out
#SBATCH --error=%x-%j.out
### Request one GPU tasks for 4 hours - dedicate 1/4 of available cores for its management
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=7
#SBATCH --gpus-per-task=1
#SBATCH --time=0-04:00:00
### Submit to the `gpu` partition of Iris
#SBATCH --partition=gpu
#SBATCH --qos=normal
print_error_and_exit() { echo "***ERROR*** $*"; exit 1; }
module purge || print_error_and_exit "No 'module' command available"
module load numlib/cuDNN # Example using the cuDNN module
[...]
Interactive jobs
In the UL HPC systems you can use the si-gpu, a wrapper for the salloc command, that allocates interactive job in a GPU node with sensible default options.