Lustre (${SCRATCH})¶
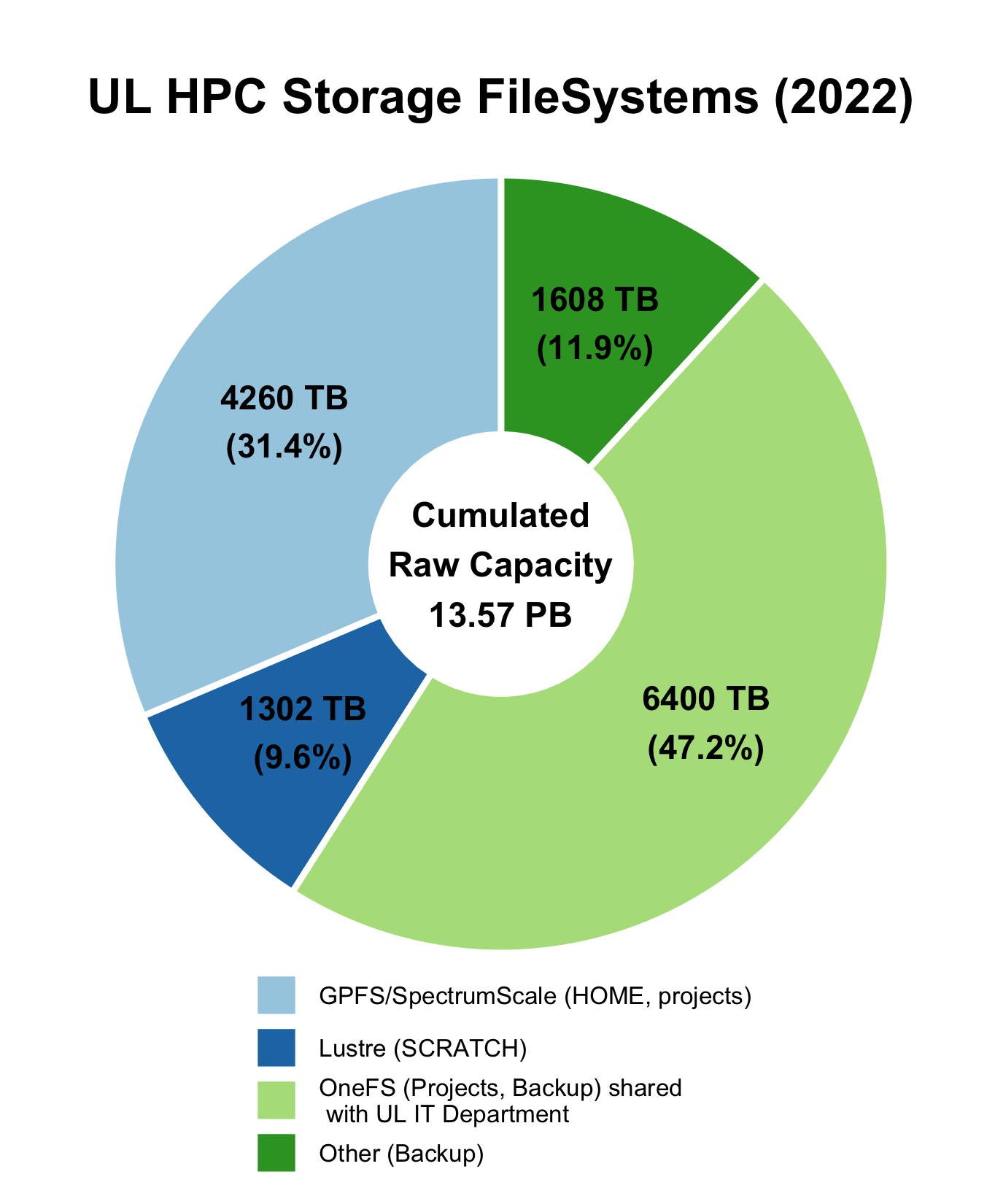
A Lustre file system is used in UL HPC clusters to provide temporary scratch data storage within jobs or job campaigns. In terms of raw storage capacities, its capacity is more than 2PB.
The Lustre file system is an open-source, parallel file system that supports many requirements of leadership class HPC simulation environments.
It is available as a global high-performance file system on all UL HPC computational clusters through a DDN ExaScaler system.1
Scratch directory (${SCRATCH})¶
The scratch area is a Lustre-based file system that provides high performance temporary storage of large files and is accessible across all cluster nodes. Use scratch to store working files and temporary large data files within single jobs or job campaigns. The scratch file system is providing redundancy and high availability that protect your data from corruption and loss of access in case of hardware failure, however, it is not a place to store files long term.
- The scratch file system is not a backup solution. Your data is not protected in case of total system loss.
- The scratch file system is oversubscribed, there is more space allocated to users than physically available. If the file system start filling up, then policies will be implemented to recover space, and your data may be deleted after a warning and a grace period that will allow you to move data to permanent storage (GPFS).
The environment variable ${SCRATCH} (which expands to /scratch/users/$(whoami)) points to a users scratch directory. The absolute path may change, but the value of ${SCRATCH} will always be correct.
Small file and random I/O
The scratch is best used to write large files in a continuous manner. Even though the Lustre file system can handle small file and random I/O better that our GPFS system, it still slows down considerably as the number of I/O operations increases. Typical example of operations with a lot random and small file I/O operations in the parallel compilation of large projects.
Prefer the locally mounted file system in /tmp for small file and random I/O.
Origin of the term scratch
The term scratch originates from scratch data tapes. People uses scratch tapes to write and read data that did not fit into the main memory, and since it was a tape, it could only perform continuous I/O. The term scratch is a bit abused in modern times as most storage systems nowadays support random access. In the case of the lustre system in UL HPC, the terms scratch serves as a reminder that the file system is best used for contiguous I/O, even though it supports random access quite well.
ULHPC ${SCRATCH} quotas and backup
Extended ACLs are provided for sharing data with other users using fine-grained control. See quotas for detailed information about inode, space quotas, and file system policies. In particular, your ${SCRATCH} directory is not backuped according to the policy detailed in the ULHPC backup policies.
General Architecture¶
A Lustre file system consists of three major functional units:
- One or more MetaData Server (MDS) nodes (typically two in high-availability configurations) that host one or more MetaData Target (MDT) devices per Lustre filesystem. These store namespace metadata, such as filenames, directories, access permissions, and file layouts. The MDT data is stored in a local disk filesystem. Unlike block-based distributed filesystems (such as GPFS/SpectrumScale and PanFS) where the metadata server controls all block allocation, the Lustre metadata server is only involved in pathname and permission checks. It is not involved in file I/O operations, which avoids I/O scalability bottlenecks on the metadata server.
- One or more Object Storage Server (OSS) nodes that store file data on one or more Object Storage Target (OST) devices. The capacity of a Lustre file system is the sum of the capacities provided by the OSTs.
- Client(s) that access and use the data. Lustre presents all clients with a unified namespace for all files and data in the filesystem, using standard POSIX semantics, and allows concurrent and coherent read/write access.
Lustre general features and numbers
Lustre utilizes a modern architecture within an object-based file system with the following features:
- Adaptable: Supports a wide range of networks and storage hardware.
- Scalable: Distributed file object handling for 100,000 clients or more.
- Stability: Production-quality stability and failover capabilities.
- Modular: Interfaces allow for easy adaptation.
- Highly Available: No single point of failure when configured with HA software.
- Big and Expandable: Allows for multiple PBs (proven >700 PB) in a single namespace.
- Open-source: Community-driven development.
Lustre provides a POSIX-compliant layer supported on most Linux flavors. In terms of raw capabilities, Lustre supports:
- Max system size: > 700 PB (Production), ~16 EB (Theoretical)
- Max file size: 16EB
- Max number of files: Per Metadata Target (MDT): 256 trillion files, up to 128 MDTs per filesystem.
When to use Lustre?
- Lustre is optimized for:
- Large files
- Sequential throughput
- Parallel applications writing to different parts of a file
- Lustre will not perform well for:
- Lots of small files
- High volume of metadata requests (though this has improved in newer versions with DNE and DoM)
- Inefficient storage usage on the OSTs (due to stripe overhead on small files)
Storage System Implementation¶
The way the ULHPC Lustre file system is implemented is depicted on the below figure.

Acquired as part of RFP 190027, the ULHPC configuration has been converted to Lustre in 2025. It is based upon:
- 1x DDN EXAScaler Lustre building block that consist of:
- 1x DDN ES7990 base enclosure and its controller pair with 4x EDR ports
- 1x DDN SS9012 disk expansion enclosure (84-slot drive enclosures)
- 365x HGST hard disks (7.2K RPM SAS HDD, 6TB, Self Encrypted Disks (SED))
- including 11x hard disks configured as hot spares
- 11x Western Digital SSDs (3.2TB SAS SSD, Self Encrypted Disks (SED))
- including 1x SSD configured as hot spare
- 8x Lustre OSTs (composed each of a single pool of 44 hard disks), 4x OSTs per controller
- 2x Lustre MDTs (one pool of 10 SSDs, split in two), 1x MDT per controller
Each ES7990 controller hosts a VM which takes simultaneously the role of MDS and OSS.
Filesystem Performance¶
The performance of the ULHPC Lustre filesystem is expected to be in the range of 12GB/s for large sequential read and writes.
IOR¶
Upon release of the system, performance measurement by IOR, a synthetic benchmark for testing the performance of distributed filesystems, was run for an increasing number of clients.

As can be seen, aggregated writes and reads exceed 10 GB/s (depending on the test).
FIO¶
Random IOPS benchmark was performed using FIO with 40 GB file size over 8 jobs, leading to the following total size of 320 GB
- 320 GB is > 2\times RAM size of the OSS nodes (128 GB RAM)

MDTEST¶
Mdtest (based on commit 8ab8f69) was used to benchmark the metadata capabilities of the delivered system.
- Command:
srun ./src/mdtest -I 10 -i 2 -z 5 -b 5 -d /mnt/scratch - Total Files/Directories: 781,200
- Iterations: 2
Performance Summary (ops/sec)
| Operation | Max | Min | Mean | Std Dev |
|---|---|---|---|---|
| Directory creation | 56,112.297 | 47,185.542 | 51,648.919 | 6,312.169 |
| Directory stat | 112,792.868 | 108,292.666 | 110,542.767 | 3,182.123 |
| Directory rename | 11,140.224 | 10,873.192 | 11,006.708 | 188.820 |
| Directory removal | 43,603.447 | 42,018.133 | 42,810.790 | 1,120.986 |
| File creation | 29,460.234 | 29,213.145 | 29,336.689 | 174.719 |
| File stat | 63,632.394 | 25,981.892 | 44,807.143 | 26,622.926 |
| File read | 54,625.837 | 52,404.959 | 53,515.398 | 1,570.398 |
| File removal | 36,589.845 | 30,940.332 | 33,765.088 | 3,994.809 |
| Tree creation | 4,213.393 | 3,825.638 | 4,019.515 | 274.184 |
| Tree removal | 1,654.506 | 1,524.128 | 1,589.317 | 92.191 |
Lustre Usage¶
Understanding Lustre I/O¶
When a client (a compute node from your job) needs to create or access a file, the client queries the metadata server (MDS) and the metadata target (MDT) for the layout and location of the file's stripes. Once the file is opened and the client obtains the striping information, the MDS is no longer involved in the file I/O process. The client interacts directly with the object storage servers (OSSes) and OSTs to perform I/O operations such as locking, disk allocation, storage, and retrieval.
If multiple clients try to read and write the same part of a file at the same time, the Lustre distributed lock manager enforces coherency, so that all clients see consistent results.
Discover MDTs and OSTs¶
ULHPC's Lustre file systems look and act like a single logical storage, but a large files on Lustre can be divided into multiple chunks (stripes) and stored across over OSTs. This technique is called file striping. The stripes are distributed among the OSTs in a round-robin fashion to ensure load balancing. It is thus important to know the number of OST on your running system.
As mentioned in the Lustre implementation section, the ULHPC Lustre infrastructure is composed of 2 MDTs and 8 OSTs. You can list the MDTs and OSTs with the command lfs df:
$ cds # OR: cd $SCRATCH
$ lfs df -h
UUID bytes Used Available Use% Mounted on
es7k2-MDT0000_UUID 5.4T 10.0G 5.3T 1% /mnt/scratch[MDT:0]
es7k2-MDT0001_UUID 5.5T 11.4G 5.4T 1% /mnt/scratch[MDT:1]
es7k2-OST0000_UUID 185.0T 52.0T 123.7T 30% /mnt/scratch[OST:0]
es7k2-OST0001_UUID 185.0T 52.0T 123.7T 30% /mnt/scratch[OST:1]
es7k2-OST0002_UUID 185.0T 52.0T 123.7T 30% /mnt/scratch[OST:2]
es7k2-OST0003_UUID 185.0T 51.9T 123.8T 30% /mnt/scratch[OST:3]
es7k2-OST0004_UUID 185.0T 52.0T 123.7T 30% /mnt/scratch[OST:4]
es7k2-OST0005_UUID 185.0T 51.9T 123.8T 30% /mnt/scratch[OST:5]
es7k2-OST0006_UUID 185.0T 52.0T 123.7T 30% /mnt/scratch[OST:6]
es7k2-OST0007_UUID 185.0T 51.9T 123.8T 30% /mnt/scratch[OST:7]
filesystem_summary: 1.4P 415.5T 989.9T 30% /mnt/scratch
File striping¶
File striping permits to increase the throughput of operations by taking advantage of several OSSs and OSTs, by allowing one or more clients to read/write different parts of the same file in parallel. On the other hand, striping small files can decrease the performance.
File striping allows file sizes larger than a single OST, large files MUST be striped over several OSTs in order to avoid filling a single OST and harming the performance for all users. There is default stripe configuration for ULHPC Lustre filesystems (see below). However, users can set the following stripe parameters for their own directories or files to get optimum I/O performance. You can tune file striping using 3 properties:
| Property | Effect | Default | Accepted values | Advised values |
|---|---|---|---|---|
| stripe_size | Size of the file stripes in bytes | 1048576 (1m) | > 0 | > 0 |
| stripe_count | Number of OST to stripe across | 1 | -1 (use all the OSTs), 1-16 | -1 |
| stripe_offset | Index of the OST where the first stripe of files will be written | -1 (automatic) | -1, 0-15 | -1 |
Note: With regards stripe_offset (the index of the OST where the first stripe is to be placed); the default is -1 which results in random selection and using a non-default value is NOT recommended.
Note
Setting stripe size and stripe count correctly for your needs may significantly affect the I/O performance.
- Use the
lfs getstripecommand for getting the stripe parameters. - Use
lfs setstripefor setting the stripe parameters to get optimal I/O performance. The correct stripe setting depends on your needs and file access patterns.- Newly created files and directories will inherit these parameters from their parent directory. However, the parameters cannot be changed on an existing file.
$ lfs getstripe dir|filename
$ lfs setstripe -s <stripe_size> -c <stripe_count> -o <stripe_offset> dir|filename
usage: lfs setstripe -d <directory> (to delete default striping from an existing directory)
usage: lfs setstripe [--stripe-count|-c <stripe_count>]
[--stripe-index|-i <start_ost_idx>]
[--stripe-size|-S <stripe_size>] <directory|filename>
Example:
$ lfs getstripe $SCRATCH
/scratch/users/<login>/
stripe_count: 1 stripe_size: 1048576 stripe_offset: -1
[...]
$ lfs setstripe -c -1 $SCRATCH
$ lfs getstripe $SCRATCH
/scratch/users/<login>/
stripe_count: -1 stripe_size: 1048576 pattern: raid0 stripe_offset: -1
In this example, we view the current stripe setting of the ${SCRATCH} directory. The stripe count is changed to all OSTs and verified. All files written to this directory will be striped over the maximum number of OSTs (16). Use lfs check osts to see the number and status of active OSTs for each filesystem on the cluster. Learn more by reading the man page:
$ lfs check osts
$ man lfs
File stripping Examples¶
-
Set the striping parameters for a directory containing only small files (< 20MB)
$ cd $SCRATCH $ mkdir test_small_files $ lfs getstripe test_small_files test_small_files stripe_count: 1 stripe_size: 1048576 stripe_offset: -1 pool: $ lfs setstripe --stripe-size 1M --stripe-count 1 test_small_files $ lfs getstripe test_small_files test_small_files stripe_count: 1 stripe_size: 1048576 stripe_offset: -1
-
Set the striping parameters for a directory containing only large files between 100MB and 1GB
$ mkdir test_large_files $ lfs setstripe --stripe-size 2M --stripe-count 2 test_large_files $ lfs getstripe test_large_files test_large_files stripe_count: 2 stripe_size: 2097152 stripe_offset: -1
-
Set the striping parameters for a directory containing files larger than 1GB
$ mkdir test_larger_files $ lfs setstripe --stripe-size 4M --stripe-count 6 test_larger_files $ lfs getstripe test_larger_files test_larger_files stripe_count: 6 stripe_size: 4194304 stripe_offset: -1
Big Data files management on Lustre
Using a large stripe size can improve performance when accessing very large files
Large stripe size allows each client to have exclusive access to its own part of a file. However, it can be counterproductive in some cases if it does not match your I/O pattern. The choice of stripe size has no effect on a single-stripe file.
Note that these are simple examples, the optimal settings defer depending on the application (concurrent threads accessing the same file, size of each write operation, etc).
Lustre Best practices¶
Parallel I/O on the same file
Increase the stripe_count for parallel I/O to the same file.
When multiple processes are writing blocks of data to the same file in parallel, the I/O performance for large files will improve when the stripe_count is set to a larger value. The stripe count sets the number of OSTs to which the file will be written. By default, the stripe count is set to 1. While this default setting provides for efficient access of metadata (for example to support the ls -l command), large files should use stripe counts of greater than 1. This will increase the aggregate I/O bandwidth by using multiple OSTs in parallel instead of just one. A rule of thumb is to use a stripe count approximately equal to the number of gigabytes in the file.
Another good practice is to make the stripe count be an integral factor of the number of processes performing the write in parallel, so that you achieve load balance among the OSTs. For example, set the stripe count to 16 instead of 15 when you have 64 processes performing the writes. For more details, you can read the following external resources:
- Reference Documentation: Managing File Layout (Striping) and Free Space
- Lustre Wiki
- Lustre Best Practices - Nasa HECC
(Obsolete) Initial ExaScaler infrastructure (as part of RFP 170035)
Until end of 2025, the Iris and Aion cluster used a different DDN ExaScaler infrastructure. Due to the end of support and warranty, we have migrated all the data to the new system described above. For the record, this is a description of the old system.

- a set of 2x EXAScaler Lustre building blocks that each consist of:
- 1x DDN SS7700 base enclosure and its controller pair with 4x FDR ports
- 1x DDN SS8460 disk expansion enclosure (84-slot drive enclosures)
- OSTs: 160x SEAGATE disks (7.2K RPM HDD, 8TB, Self Encrypted Disks (SED))
- configured over 16 RAID6 (8+2) pools and extra disks in spare pools
- MDTs: 18x HGST disks (10K RPM HDD, 1.8TB, Self Encrypted Disks (SED))
- configured over 8 RAID1 pools and extra disks in spare pools
- Two redundant MDS servers
- Dell R630, 2x Intel Xeon E5-2667v4 @ 3.20GHz [8c], 128GB RAM
- Two redundant OSS servers
- Dell R630XL, 2x Intel Xeon E5-2640v4 @ 2.40GHz [10c], 128GB RAM
| Criteria | Value |
|---|---|
| Power (nominal) | 6.8 KW |
| Power (idle) | 5.5 KW |
| Weight | 432 kg |
| Rack Height | 22U |



$ lfs df -h
UUID bytes Used Available Use% Mounted on
lscratch-MDT0000_UUID 3.2T 16.3G 3.1T 1% /mnt/lscratch[MDT:0]
lscratch-MDT0001_UUID 3.2T 12.1G 3.1T 1% /mnt/lscratch[MDT:1]
lscratch-OST0000_UUID 57.4T 27.4T 29.4T 49% /mnt/lscratch[OST:0]
lscratch-OST0001_UUID 57.4T 25.7T 31.2T 46% /mnt/lscratch[OST:1]
lscratch-OST0002_UUID 57.4T 25.4T 31.5T 45% /mnt/lscratch[OST:2]
lscratch-OST0003_UUID 57.4T 23.7T 33.2T 42% /mnt/lscratch[OST:3]
lscratch-OST0004_UUID 57.4T 27.7T 29.2T 49% /mnt/lscratch[OST:4]
lscratch-OST0005_UUID 57.4T 29.2T 27.6T 52% /mnt/lscratch[OST:5]
lscratch-OST0006_UUID 57.4T 26.1T 30.7T 46% /mnt/lscratch[OST:6]
lscratch-OST0007_UUID 57.4T 25.7T 31.2T 46% /mnt/lscratch[OST:7]
lscratch-OST0008_UUID 57.4T 25.5T 31.4T 45% /mnt/lscratch[OST:8]
lscratch-OST0009_UUID 57.4T 25.6T 31.3T 45% /mnt/lscratch[OST:9]
lscratch-OST000a_UUID 57.4T 26.0T 30.8T 46% /mnt/lscratch[OST:10]
lscratch-OST000b_UUID 57.4T 25.0T 31.9T 44% /mnt/lscratch[OST:11]
lscratch-OST000c_UUID 57.4T 25.2T 31.6T 45% /mnt/lscratch[OST:12]
lscratch-OST000d_UUID 57.4T 24.8T 32.0T 44% /mnt/lscratch[OST:13]
lscratch-OST000e_UUID 57.4T 24.3T 32.6T 43% /mnt/lscratch[OST:14]
lscratch-OST000f_UUID 57.4T 25.2T 31.6T 45% /mnt/lscratch[OST:15]
filesystem_summary: 919.0T 412.4T 497.3T 46% /mnt/lscratch
-
A short history of Lustre
Lustre was initiated & funded by the U.S. Department of Energy Office of Science & National Nuclear Security Administration laboratories in mid 2000s. Developments continue through the Cluster File Systems (ClusterFS) company founded in 2001. Sun Microsystems acquired ClusterFS in 2007 with the intent to bring Lustre technologies to Sun's ZFS file system and the Solaris operating system. In 2010, Oracle bought Sun and began to manage and release Lustre, however the company was not known for HPC. In December 2010, Oracle announced that they would cease Lustre 2.x development and place Lustre 1.8 into maintenance-only support, creating uncertainty around the future development of the file system. Following this announcement, several new organizations sprang up to provide support and development in an open community development model, including Whamcloud, Open Scalable File Systems (OpenSFS, a nonprofit organization promoting the Lustre file system to ensure Lustre remains vendor-neutral, open, and free), Xyratex or DDN. By the end of 2010, most Lustre developers had left Oracle.
WhamCloud was bought by Intel in 2011 and Xyratex took over the Lustre trade mark, logo, related assets (support) from Oracle. In June 2018, the Lustre team and assets were acquired from Intel by DDN. DDN organized the new acquisition as an independent division, reviving the WhamCloud name for the new division.